Effective Webapp Flow - 25h Sprint Retrospective
Programming is easy and effortless when things go right. This happy path is where AI shines. There are sandboxed environments of development, coheasive ecosystems of tools, frameworks, libraries, which play well together to achieve a certain goal. There are also generally accepted patterns and ways of doing things. While you’re working within such a sandbox, exactly following the purposes it was built for, you’re on the happy path.
While enjoyable, the work within the sandbox is not really what powers the world of software. Sandbox needs to be evolved, breaks sometimes, someone needs to maintain it - and that is hard, not at all something AI in its current shape can do.
Worse, not every sandbox leads to a good and sustainable software to be developed inside. Every sandbox has a certain way of creating things that’s supposed to be used by its developers. This is the philosophy, constraints, principles, design decisions baked into the system. It is around those that the tooling of the sandbox is built, shaping the developer experience of the users.

One of the most important properties a software development sandbox has is the complexity of the software developed in that sandbox. Some ways of doing software engineering lead to software that can scale without a significant complexity buildup, while with others the complexity scales with the volume of code. Modern AI solutions generally do not understand things like complexity or philosophy well, leading to a blow-up of complexity if relied upon entirely when developing software.
However, AI also is a great leverage when used right, as it does decrease the amount of straightforward work that doesn’t involve architectural decision-making. For the past month or so, I’ve been trying to develop an approach to software engineering of web applications that would click with my personality, provide a solid theoretical foundation for complexity management, and leverage AI for efficiency. The journey is ongoing, and in this article I’m summarizing the insights from the first 25 hours of engineering time.
Prior Approach
One great source of complexity when developing web apps is javascript and its ecosystem. I’ve tried frameworks like React, Vue, Svelte in the past, and all of them lead to complexity blow-up. What I found remarkable is that there was no single accepted, well thought-through way of doing things. I’ve had a particularly bad experience when it came to state management and there was a ton of libraries for doing it, all handling the centralization-decentralization, propagation, caching of state in very different ways.
Complexity level starts with the theoretical foundations of the programming language of choice. If the language is well thought-through and is designed for expressing complex ideas and building complex applications in a scalable way, the language’s ecosystem will follow.
What was a source of progress in my complexity management experience was Elixir’s Phoenix framework. Phoenix does not rely on Javascript for client-side experience in its philosophy. Instead, all updates to the HTML DOM are server-rendered, shipped over the wire to the client, and plugged in their appropriate places.
With the Javascript’s inherent complexity eliminated, the one left was that of Elixir and Phoenix. A neat functional language building on a very mature Erlang ecosystem, Elixir has its own philosophy about how a webapp should be structured. The complexity experience without Javascript was good, but not great. Lacking a strong type system, Elixir still generated complexity when the size of the app grew. To tackle that complexity, they have the Ash framework, however, it lacks any solid theoretical basis and seems to be a lump of commonly used routines that felt like a patchwork plugging the holes rather than an integral, solid piece of work.
The move to eliminate Javascript was in the right direction, however, as the amount of related complexity gone was significant.
HMDA with htmx and Scala
It’s possible to recreate the experience of having no significant Javascript by using htmx which does essentially the same thing as Phoenix’s LiveView but in a server-agnostic way. htmx extends the syntax of HTML to also describe AJAX requests to the server, and substitute DOM targets with the HTML response.
When I first discovered it, I was surprised how well thought-through it is theoretically. Turns out, it follows the HyperMedia Driven Applications (HMDA) approach, which, in turn, is rooted in RESTful approach to APIs. Most of the APIs of the modern web are not, in fact, RESTful as they violate some of the original REST constraints. If you’re interested in the rabbit hole, their website has a number of essays to read more about the philosophy.
Anyway, htmx gives us a LiveView that is language-agnostic. So currently, I was able to further reduce the complexity by using Scala and its strong types to put the server-side app in the nice shape.
The New System Design
The dummy app I’m using as a playground to test the approach is a flashcards app for language learning.
The design is visual-first. It starts from drawing the mockups of the UX flow in Excalidraw using Obsidian and Obsidian Excalidraw Plugin to keep things organized.

From the UX mockup, the data model is designed

According to the RESTful architecture, an app can be thought about as a set of endpoints. Each endpoint is stateless on the server-side and is fully described by its HTTP method, path and headers. I’m also adoping the Hypermedia as the Engine of Application State (HTEOAS), specifically driven by hypertext only. Meaning, no JSON - server responds directly with HTML.
Surprisingly, lots of webapp development complexity came from the need to serialize JSON, maintain client-side model and the need to interpret that model on the client side to render it. Eliminating JSON allowed to remove all that, leading to less complexity.
Anyway, the next step is, therefore, to spec out all the webapp endpoints next to the UX flow.

The above process provides all the required information to start developing the app. The development loop is then quite simple. Because they are stateless (meaning no session state is stored in server RAM), endpoints are isolated one from another, and can be tackled one by one in an iterative process of:
- Preparing the data - database migrations for the permanent schema, as well as the dev migrations with the dummy data.
- Implementing the logic.
- Writing the tests.
Architecture
The core part of the app is the endpoints.scala file containing all the app endpoints. Each endpoint name is a Tapir endpoint, and therefore a plain old Scala value. Th naming is as follows:
val snake_case_HTTP_path_METHOD
For example:
val decks_id_GET = ... // GET /decks/{id}
Snake case allows for a better visual mapping between the Excalidraw spec and the endpoing value name. HTTP method goes last since that way, the method names are get aligned nicely in VS Code outline or when enumerated in a list. Consider:
List(
decks_GET,
decks_POST,
decks_new_GET,
)
versus:
List(
GET_decks,
POST_decks,
GET_decks_new,
)
Also:
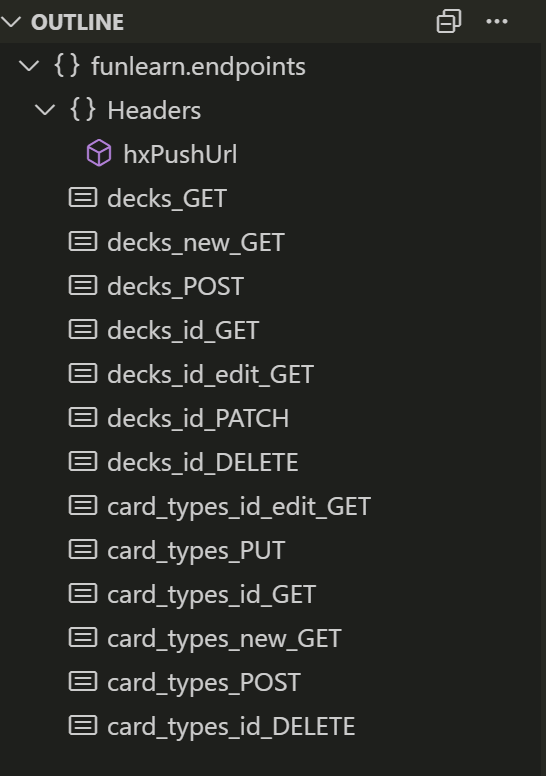
Endpoints have companion methods: HTML methods produce HTML (implemented using scalatags) with which to respond whereas IMPL objects encapsulate the business logic of the endpoint. Both can be omitted in case the implementation is simple enough and can be fused into the endpoint. For example:
val decks_POST = endpoint
.post.in("decks").in(formBody[Seq[(String, String)]])
.out(header[String](HeaderNames.Location))
.out(statusCode(StatusCode.SeeOther))
.handleSuccess:
(body: Seq[(String, String)]) =>
val data = IMPL_decks_POST.mkData(body)
val cardTypeId = IMPL_decks_POST.impl(data)
s"/card_types/$cardTypeId/edit"
val decks_id_GET = endpoint
.get.in("decks" / path[Long]).out(stringBody)
.out(header(Header.contentType(MediaType.TextHtml)))
.out(header[String](Headers.hxPushUrl))
.handleSuccess:
(deckId: Long) =>
val deck = decksRepo.findById(deckId).get
val cardTypes = cardTypesRepo.getCardTypesByDeckId(deckId)
val body = HTML_decks_id(deck, cardTypes).toString
(body, s"/decks/$deckId")
These companion methods also follow the same naming patterns derived from the HTTP endpoint name itself, just the action type, HTML or IMPL now goes before the endpoint name, as they are not expected to ever appear as a part of one list or IDE outline.
HTTP endpoints spec is a single source of truth as far as navigation is concerned. The unit of navigation is a symbol, not a file, therefore, we are less concerned about constructing file hierarchies and place all the methods of the same kind in one file, endpoints.scala or services.scala. html is an exception as it’s more intuitive to have every HTML page in its proper file.
Of course there is a also a database layer, CRUD operations being partially derived using Magnum.
AI
AI is bad at making sound architectural decisions on its own, but is really good in pattern-recognition. A side effect from the above architecture is that code becomes highly regular, namings - mapped to the Excalidraw drawing-spec.
So the approach to AI automation is two-fold:
- Write the initial MVP of the project by hand entirely, not relying on any AI support.
- Once there is a ready seed codebase, increase reliance on AI to implement other endpoints.
Some tips along the way:
- If your mockups and endpoints are specced in Excalidraw, take a screenshot and feed it to Cursor IDE’s chat. Its multimodal capability will help it extrapolate your existing codebase and implement the required features.
- You can use Cursor’s Rules feature to explicitly instruct it to follow your existing codebase and style.
Summary
The approach outlined focuses on eliminating as much complexity as possible, as well as rapid prototyping. Great part of complexity comes from Javascript ecosystem and suboptimal theoretical foundation of some server-side languages. Some extra complexity comes from the necessity to interpret JSON on the client side. By using Scala and htmx, it’s possible to eliminate much of those.
By using RESTful, HMDA and HATEOAS theoretical foundation, it’s possible to achieve independence between the endpoints. Designing in Excalidraw according to those foundations as well as establishing naming conventions results in a highly regular code that AI loves. By explicitly not relying on AI at the very beginning of development, then using Excalidraw specs, it’s possible to produce high-quality code while still leveraging AI for efficiency.
There are a few areas of app development I’m still looking an efficient approach to. The biggest ones are UI, testing and client-side scripting.
For the client-side scripting, so far Scala.js works best. The complexity is kept down by limiting JS to basic decorative interactions such as animations.
For UI I’m currently using Pico, a minimalistic semantic framework for decent default styling. However it’s quite limited and probably better alternatives exist. For testing, most probably it’s going to be Selenium with focus on integration tests backed by in-memory test databases.
More updates will follow on the above technique as the project progresses.